
9·
5 days ago“Moi je voulais pas, c’est les autres y m’ont forcé”
24€ dans les points de vente pas encore tenus par un milliardaire d’extrême droite.
“Moi je voulais pas, c’est les autres y m’ont forcé”
24€ dans les points de vente pas encore tenus par un milliardaire d’extrême droite.
Seulement 25% mais on file le ministère de l’Intérieur à un des leurs…
Bah dans tous les sondage, on pose une question sur un mot et on s’intéresse à ce qu’il évoque pour les gens. A priori non, on a pas parlé spécifiquement de la 5e ni de la démocratie représentative. De la démocratie en général.
Dans mon cas une algocratie anarcho-communiste mais je pense que je vais juste cocher la case “autre”
Il faut le dire vite. Il y a des anarchistes qui sont contre la démocratie, souvent sous-entendu contre la “dictature de la majorité” (qui n’est qu’une des définitions existantes). Makhno également dénonçait la démocratie comme un outil de la bourgeoisie, les plus charitables de ses commentateurs disent que c’est la démocratie représentative qu’il critiquait.
Bon, la plupart vont généralement être bien plus alignés avec des démocrates et leurs valeurs qu’avec des autoritaristes et beaucoup reconnaissent que leurs pratiques peuvent être appelées démocratiques, mais y a un débat qui existe quand même.
Oui c’est vrai, ma formulation est maladroite.
Originaire de Lyon, a créé un groupe antifasciste lyonnais. Il est allé dans une circo que LFI a proposé mais c’est un Lyonnais.
Lyon nous a aussi donné notre premier députés anti-fa (ouvertement et littéralement). Lyon est une terre de contrastes.

;-)
Alors je sais pas si c’est à ça que tu penses quand tu parles de règles physiques, mais à un moment je réfléchissais un peu à un univers de combats de magiciens, dans une ambiance à la Magic The Gathering, où on progresse et on s’affronte non pas en se tapant dessus avec des armées mais en influençant des biomes respectifs…
D’un coté je suis très tenté d’explorer des concepts de gameplay un peu nouveau, autant sur une première séance, je préfère rester en terrain un peu connu!
Comme tu le sens! De toutes façons le stream sera long, si jamais l’envie te prend de dire quelque chose t’aura largement le temps de créer un compte pendant!
18h vendredi prochain (1er novembre).
Non twitch ne demande pas de compte pour suivre le streaming, par contre il en demande un (gratuit) pour participer au chat. Désolé, j’espérais qu’on puisse expérimenter une plateforme un peu plus libre en la matière mais on n’a pas eu le temps de mettre ça en place.
ping @lascapi@jlai.lu et @Sravoryk@jlai.lu qui avaient l’air intéressés.
Si ça pouvait ouvrir le débat de sa dissolution, ce serait salvateur. Avant 1941, on faisait avec les polices municipales et la gendarmerie nationale. Le pêché originel de la police, d’avoir été un organe conçu par un état autoritaire pour sa propre sauvegarde, semble irrémissible.

Ah super ça! Installée, merci!
Dans mon premier taff (en présentiel) Je suis passé de super productif et motivé à glandeur-expert suite à un changement de management. Je peux vous assurer que même sans pause café, glander au boulot en présentiel est relativement facile.
Y a pas de raccourci: c’est la qualité du management (et son empathie réelle) qui détermine la motivation des employés, en présentiel ou en télétravail.
Je ne sais pas mais l’USB sait.
Mais du coup, mieux vaut des landes ou une forêt industrielle?
Si ton patron te paye en liquide, y a des chances que ce soit très louche.
Mais oui perso je suis pas fan du ton “si vous utilisez pas un système qui force à passer par le système bancaire, vous êtes un criminel!”







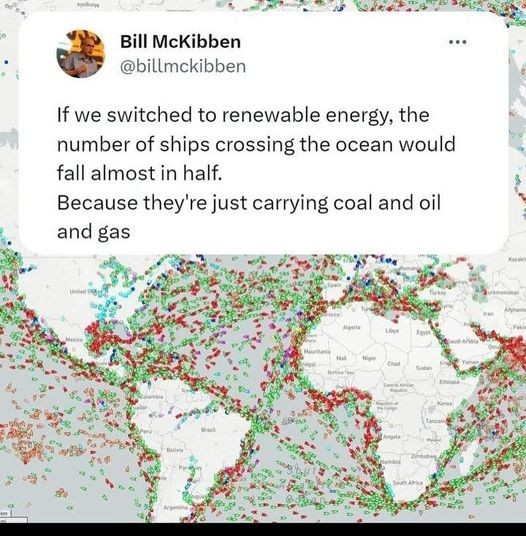{kind=link}
{kind=link}
On va retenter le coup, mais je pense qu’il faut qu’on se concentre à faire un résumé youtube. Je pense que je vais pas faire la pub des prochains jusqu’à ce que je sois content du résultat.
Le pire c’est que j’étais tellement déçu au retour que de retour chez moi j’ai fait plein de trucs (en pygame et OpenGL, que je connais bien) qui ont immédiatement bien marché!